微服务构架下的Serveless实践
目前的软件构架,什么样的构架方式是最受关注?答案自然是微服务了。似乎人人都在谈微服务,维护老系统的开发人员,在思考如何将系统迁移到微服务的构架下。开发新项目的,自热而然已经在的构架设计上,会采用微服务的构架方式了。网络上讨论微服务的文章现在是汗牛充栋,这篇文章不打算更多的讨论什么是微服务,它好处,它的问题,而想讨论下我们在微服务构架下在实现上一些演进的方式,希望能带来更多的思考。
微服务构架下的数据处理业务
在互联网应用下,数据越来越成为驱动业务的一个重要的驱动力了。CEO要需要依靠数据来做出战略的决定,运营人员需要看数据来做出运营方案,开发人员需要根据交互数据来调整开发方案。所以可以说数据处理服务慢慢的成为一个企业IT系统中的重要环节。笔者之前参与的项目就是为了开发出这样一套数据的ETL系统,为企业的业务人员服务。
具体来说,我们使用了第三方的用户数据追踪服务,来为我们追踪用户的行为,而每天他们都会为我们提供一份用户行为的数据文件,我们需要拿到这些数据,加上我们自己的产品数据,就能清楚的让我们的运营人员看到,我们有哪些产品是最受欢迎的,哪哪些产品的访问量较低等等。那么最初我们是怎么设计的技术方案的呢?
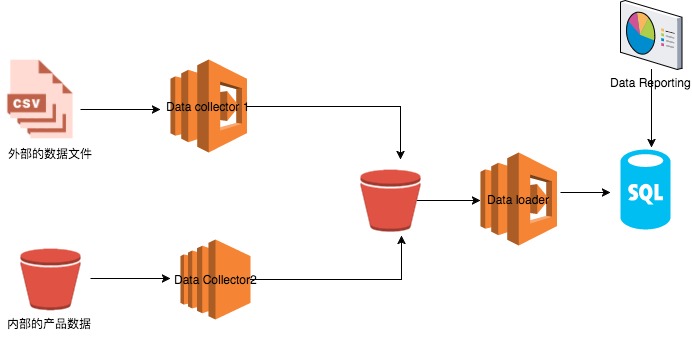
传统的微服务架构

我们将业务拆分为3个独立的微服务,2个data collector,1个data loader, 都分别的部署在EC2的Instance上,将中间数据存储在一个外部的S3 bucket上(AWS的数据存储)最后将数据保存在我们的数据库中,在数据库之上我们使用专门的BI工具来制作Report。至于为什么这样拆分微服务,这样拆分的好处是什么,这篇文章这不进行详细的讨论。我们第一个数据服务就是按照这样的构架进行设计和实践的。当系统上线服务以后,我们发现了里边的一些问题。
在我们这套系统中,Data Collector 2 每天的执行时间较长需要1个小时左右的时间,而 Data Collector 1 每天的执行时间较短,通常执行时间不会超过1分钟,但是由于外边的数据源的更新时间是不确定的,所以虽然我们服务实际的有用时间只有仅仅的一到两分钟,但是也不得不让instance24小时全天运行。
可以看到,我们的服务每天实际有效的时间只有一个小时,其他23个小时实际上是在浪费资源,如何改善这样的情况呢?首先我们想到了让服务定点运行的方法。由于我们外服数据源的更新特点,虽然它的更新时间是不确定的,但是它在一个特定的时间点前是一定会更新的。所以基于这样的情况,我们将服务的运行时间改为定点运行,这样是不是就能解决问题了呢?
然而现实总不是那么美好,因为我们服务间是有依赖关系的,data loader 是依赖于我们data Collector的处理结果的,当我们把运行方式改为定点运行后,带来的问题是,一旦data Collector的运行状态出现了问题,例如运行时间过长,运行中出现错误,那么data loader必然出错。并且改为定点运行后,我们的数据更新必然有延迟。
那么如何解决这些问题呢?
Serveless的系统架构
2016年Serveless Architectures的提出引发了对于软件构建的关注,那么什么是Serveless Architectures呢?现在还没有一个明确的定义,但是就我的理解而言,Serveless顾名思义,就是没有Serve的构架方式。我们业务逻辑代码并不是执行在一个Server上了,例如一台EC2的instance。而是运行在一些基于事件驱动的,无状态的第三方计算服务上,也就是Function as a Service。概念可能比较抽象,举例来说就是AWS的Lambda,Lamnda可是说是Function as a Service的典型代表。那么下边我就来介绍下,我们是如何使用Lambda来改进上边的数据处理系统。
其实也很简单,我们将Data Collector 和 Data loader用Lambda进行了替换,有哪些好处呢?第一点因为我们的基础架构是架构在AWS上的所以,Lambda提供了很多事件驱动的机制,例如,S3上一个数据的变化可以触发一个事件,SNS的一条消息可以触发一个时间等等,在使用Lambda后,我们就可以讲原来基于时间的数据处理流程,转变为基于事件的数据处理流程,这样一方面可以保证我们数据更新的实时性,另一方面可以大大节省资源,由于Lambda是按照触发次数收费的,所以在我们的这个用例下,可以大大减少花费。可能细心的读者想问为什么我们data Collector 2 没有使用Lambda进行替换呢?这是因为它的业务逻辑比较复杂,每次运行的时间较长,而Lambda的最长执行时间是5分钟,所以在这种情况下,就不适合使用Lambda进行替换了。
实时数据处理下Serveless构建
在初识Serveless 构建的好处之后,我们开始在其他方面应用的尝试,比较典型的一个例子就是在实时数据处理业务下的Serveless构架,目前在我们有原来越多的实时数据需要处理,例如记录用户行为的log数据,实时的数据分析等等。在我们业务下,同样有这样的需求,我们需要实时的跟踪一个外部的数据源API,实时根据它的数据变化来更新我们的数据,下边就是我们在解决这样业务场景下的Serveless构架。

在我们的构架设计中,我们使用一个lambda来跟踪外部数据源的数据变化,并将其推到AWS Kinesis Stream里,AWS Kinesis 会触发第二个lambda进行相应的数据处理,并把数据存储到数据库中,值得注意的是由于Lambda是可以根据需求自动伸缩的,所以Lambda会根据Kinesis的需求来自动的scaling,到流中的数据量大时,触发的lamnda会相应增大。当数据量小时,触发的lambda会相应的减少。这就体现了Serveless 构架下的另一个好处,可以相对简单的,自动的进行伸缩扩展。
#Web系统的Serveless构架 上文我们更多的是讨论,对于数据处理系统下的Serveless构架,那么对于Web系统来说,这种我们最为熟悉和常见的IT系统它是如何能不能用Serveless的构建来进行实现呢?我们来看下边的例子。我们先来看看经典的传统的例子。 
在传统的实现中,我们会利用load Blancer来做负载均衡,然后后边的app在AutoScaling Group中,根据request的情况来做自动的Scaling,这种模式已经是十分成熟了。那么我们看看在Serveless的构架下该如何设计呢?

在serveless的构架下,一般我们的frontend app的资源包括Html,js,css是部署在S3 bucket下的。前端通过http请求向后台请求数据。后台通过API GateWay定义对外的endpoint,同时每个endpoint会触发一个lamnda进行数据操作,例如图中的GET,和POST请求会触发两个不同lambda。 在这种构架下,带来的第一点好处就是,我们不必自己担心Scaling的问题了,以前我们要自己去建立AutoScaling Group根据请求来进行不断的挑战,而在Serveless构架下我们就可以很大程度上不必担心这样的问题了。同样可以不必自己去监控Instance了,云平台上相应的服务替代我们做了这些工作。
但是是不是我们现在就要完全的拥抱Serveless构架,将我们所以得Service都变成这样呢?我觉得并不一定是这样的,Serveless在给我们带来好处的同时,也给我们来了很多的问题,例如上边的构架图,我们可以看到已经十分复杂了,这里每一块我们都要考虑它的deployment,logging,monitoring等等的问题,这无疑给带了更多的复杂度。
的确就像以往任何一种新的技术一样,Serveless 不是银弹,再给我们带了优势和益处的同时,也相应的带了不少的问题。选不选择还是要安装业务场景来具体分析,希望本文我们的实践经验能给您带来更多的思考。
Comments powered by Disqus.